StoryDiffusion: Consistent Self-Attention for Long-Range Image and Video Generation
StoryDiffusion: Consistent Self-Attention for Long-Range Image and Video Generation
StoryDiffusion: Consistent Self-Attention for Long-Range Image and Video Generation
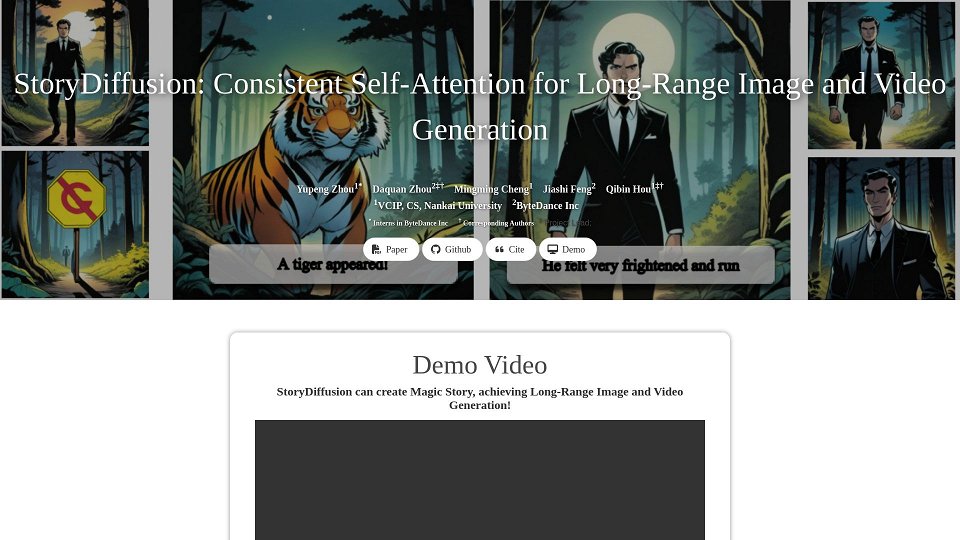
StoryDiffusion: Consistent Self-Attention for Long-Range Image and Video Generation Introduction
StoryDiffusion is a novel approach for long-range image and video generation that leverages consistent self-attention mechanisms. This technique ensures coherence and consistency in generated content, particularly in scenarios involving character styles, attires, and scene transitions. The core innovation lies in maintaining visual consistency over extended sequences, making it ideal for tasks like comic generation and long-form video synthesis. StoryDiffusion excels in generating high-quality, visually cohesive content suitable for various applications, including storytelling and content creation.
StoryDiffusion: Consistent Self-Attention for Long-Range Image and Video Generation Use Cases
Creating comics with consistent characters and narratives
Generating long videos with smooth transitions and visual coherence
Synthesizing visual content for storytelling and creative applications
Core features of StoryDiffusion: Consistent Self-Attention for Long-Range Image and Video Generation
Consistent Self-Attention for Long-Range Coherence
High-Quality Image and Video Generation
Preservation of Character Styles and Attires
Comic Generation with Cohesive Storytelling
Long Video Synthesis with Semantic Motion Prediction
StoryDiffusion: Consistent Self-Attention for Long-Range Image and Video Generation Frequently Asked Questions
What is StoryDiffusion?
StoryDiffusion is a new approach for creating long-form images and videos using consistent self-attention. This means it can generate images and videos where characters and styles remain visually consistent over a long sequence.
How does StoryDiffusion work?
StoryDiffusion uses a special mechanism called 'consistent self-attention' that helps it remember and maintain visual elements like character appearance and style across multiple frames. This ensures that generated content is cohesive and visually pleasing.
Is my data kept private?
The provided information does not specify details regarding data privacy.
What is the pricing for StoryDiffusion?
The provided information does not mention any pricing details.
Users who use StoryDiffusion: Consistent Self-Attention for Long-Range Image and Video Generation
Artists and content creators
AI researchers and developers
Enthusiasts in computer graphics and vision