StoryDiffusion: 一致性自我注意力用於長範圍圖像和視頻生成
StoryDiffusion: 一致性自我注意力用於長範圍圖像和視頻生成
StoryDiffusion: 一致性自我注意力用於長範圍圖像和視頻生成
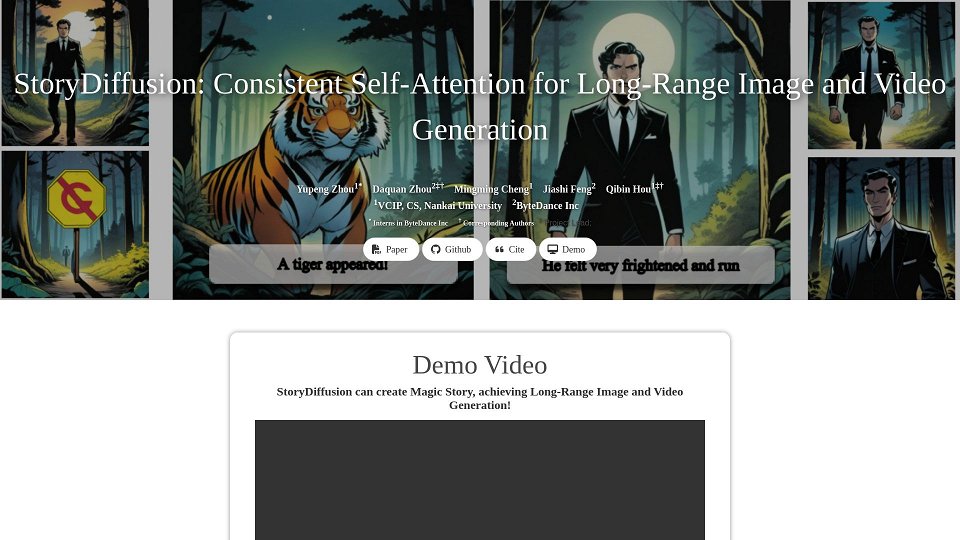
StoryDiffusion: 一致性自我注意力用於長範圍圖像和視頻生成 介紹
StoryDiffusion是一種利用一致性自我注意力機制進行長範圍圖像和視頻生成的新方法。這種技術確保生成的內容在角色風格、服飾和場景轉換等方面具有一致性和連貫性。其核心創新在於在延長的序列中保持視覺一致性,使其非常適合漫畫生成和長篇視頻合成等任務。StoryDiffusion擅長生成高質量、視覺連貫的內容,適用於各種應用,包括故事講述和內容創作。
StoryDiffusion: 一致性自我注意力用於長範圍圖像和視頻生成 使用案例
使用一致的角色和敘事創建漫畫
生成具有平滑轉換和視覺連貫性的長視頻
合成用於故事講述和創意應用的視覺內容
StoryDiffusion: 一致性自我注意力用於長範圍圖像和視頻生成 的核心功能
一致性自我注意力用於長範圍連貫性
高質量圖像和視頻生成
保留角色風格和服飾
具有連貫故事講述的漫畫生成
具有語義運動預測的長視頻合成
StoryDiffusion: 一致性自我注意力用於長範圍圖像和視頻生成 常見問題
什麼是StoryDiffusion?
StoryDiffusion是一種使用一致性自我注意力的新方法,用於創建長篇圖像和視頻,使角色和風格在長序列中保持視覺一致。
StoryDiffusion如何工作?
StoryDiffusion使用一種稱為“一致性自我注意力”的特殊機制,幫助它記住和保持視覺元素,如角色外觀和風格,在多個幀之間。這確保生成的內容具有連貫性和視覺上的滿意度。
我的數據是否保持私密?
提供的信息未具體說明數據隱私的詳細信息。
StoryDiffusion的價格是多少?
提供的信息未提及任何價格細節。
使用StoryDiffusion: 一致性自我注意力用於長範圍圖像和視頻生成的用戶
藝術家和內容創作者
人工智慧研究人員和開發人員
電腦圖學和視覺愛好者