StoryDiffusion: Konsistente Selbst-Aufmerksamkeit für die Generierung von Bildern und Videos über große Distanzen
StoryDiffusion: Konsistente Selbst-Aufmerksamkeit für die Generierung von Bildern und Videos über große Distanzen
StoryDiffusion: Konsistente Selbst-Aufmerksamkeit für die Generierung von Bildern und Videos über große Distanzen
StoryDiffusion: Konsistente Selbst-Aufmerksamkeit für die Generierung von Bildern und Videos über große Distanzen Einführung
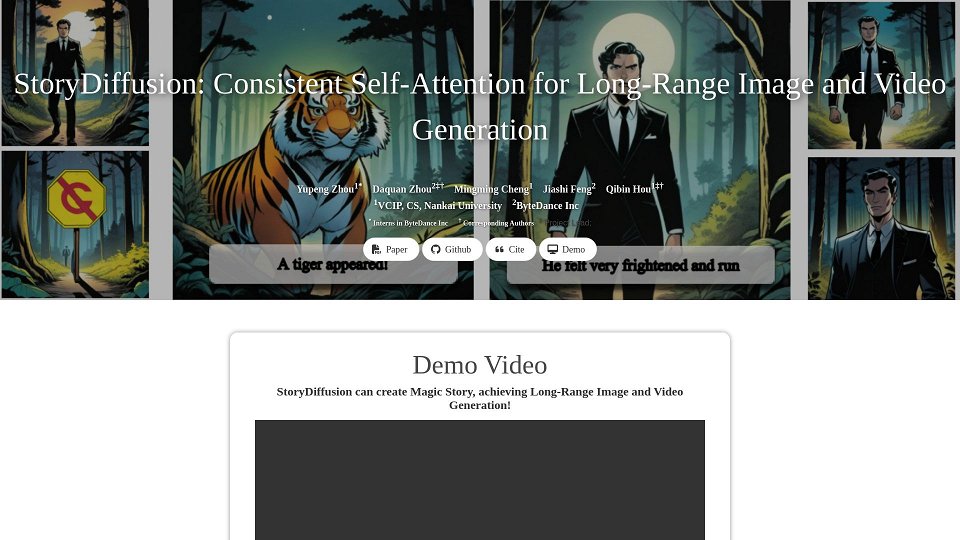
StoryDiffusion ist ein neuartiger Ansatz zur Generierung von Bildern und Videos über große Distanzen, der auf konsistente Selbst-Aufmerksamkeitsmechanismen setzt. Diese Technik gewährleistet Kohärenz und Konsistenz im generierten Inhalt, insbesondere in Szenarien mit Charakterstilen, Kleidung und Szenenübergängen. Die Kerninnovation besteht darin, die visuelle Konsistenz über längere Sequenzen hinweg aufrechtzuerhalten, was es ideal für Aufgaben wie die Comic-Generierung und die Synthese von Langformvideos macht. StoryDiffusion zeichnet sich durch die Generierung hochwertigen, visuell zusammenhängenden Inhalts aus, der für verschiedene Anwendungen, einschließlich Storytelling und Content-Erstellung, geeignet ist.
StoryDiffusion: Konsistente Selbst-Aufmerksamkeit für die Generierung von Bildern und Videos über große Distanzen Anwendungsfälle
Erstellung von Comics mit konsistenten Charakteren und Erzählungen
Generierung langer Videos mit fließenden Übergängen und visueller Kohärenz
Synthese von visuellem Inhalt für Storytelling und kreative Anwendungen
Kernfunktionen von StoryDiffusion: Konsistente Selbst-Aufmerksamkeit für die Generierung von Bildern und Videos über große Distanzen
Konsistente Selbst-Aufmerksamkeit für kohärente Langstrecken-Generierung
Generierung hochwertiger Bilder und Videos
Erhaltung von Charakterstilen und Kleidung
Comic-Generierung mit zusammenhängender Storytelling
Langformvideo-Synthese mit semantischer Bewegungsvorhersage
StoryDiffusion: Konsistente Selbst-Aufmerksamkeit für die Generierung von Bildern und Videos über große Distanzen Häufig gestellte Fragen
Was ist StoryDiffusion?
StoryDiffusion ist ein neuer Ansatz zur Erzeugung von Bildern und Videos über große Distanzen unter Verwendung von konsistenter Selbst-Aufmerksamkeit. Das bedeutet, dass es Bilder und Videos generieren kann, bei denen Charaktere und Stile über eine lange Sequenz hinweg visuell konsistent bleiben.
Wie funktioniert StoryDiffusion?
StoryDiffusion verwendet einen speziellen Mechanismus namens 'konsistente Selbst-Aufmerksamkeit', der ihm hilft, visuelle Elemente wie das Erscheinungsbild und den Stil von Charakteren über mehrere Frames hinweg zu merken und beizubehalten. Dadurch wird gewährleistet, dass der generierte Inhalt zusammenhängend und visuell ansprechend ist.
Werden meine Daten privat gehalten?
Die bereitgestellten Informationen enthalten keine Details zum Datenschutz.
Was kostet StoryDiffusion?
Die bereitgestellten Informationen enthalten keine Angaben zu den Preisen.
Benutzer, die StoryDiffusion: Konsistente Selbst-Aufmerksamkeit für die Generierung von Bildern und Videos über große Distanzen verwenden
Künstler und Content-Ersteller
KI-Forscher und Entwickler
Enthusiasten für Computergrafik und Vision